




Transparencia Predictiva: un nuevo modelo
La historia de la transparencia en México ha atravesado diferentes etapas y modelos teórico-prácticos. Inicialmente, el paradigma se centró en atender lo que la sociedad solicitaba a través de mecanismos que garantizaban su derecho a la información, lo que eventualmente se denominó “transparencia reactiva”.
Posteriormente, esta fue concebida como una herramienta para promover la rendición de cuentas de las autoridades, orientando la publicación de información a través de obligaciones legales específicas que, en su momento, evolucionaron en obligaciones de transparencia, dando paso a la “transparencia activa”.
Más tarde, como resultado de un entendimiento más amplio de la transparencia y con una perspectiva de política pública, se avanzó hacia un enfoque de difusión proactiva de información. La premisa era que las instituciones públicas debían realizar esfuerzos adicionales para identificar, generar, procesar, publicar y difundir información acorde con las necesidades y contextos de la población destinataria, sin que necesariamente mediara una solicitud de acceso a la información.
Bajo este enfoque, denominado “transparencia proactiva”, la sociedad se convirtió en el punto de partida y finalidad de la publicación de información por parte de las instituciones públicas. Para ello, resulta fundamental analizar las características de los grupos poblacionales solicitantes, lo que permite ajustar cada dato o documento publicado para dotarlo de mayor calidad y utilidad.
¿Qué es la Transparencia Predictiva?
A esta nueva vertiente de la transparencia la denominamos “transparencia predictiva”, la cual, hemos propuesto como un modelo de gestión de información pública que, mediante el uso de inteligencia artificial y análisis de datos, permite predecir y anticipar futuras necesidades de información para publicar, de manera oportuna, insumos estratégicos incluso antes de que sean solicitados. Este enfoque trasciende la transparencia reactiva, activa y proactiva, al emplear modelos que identifican patrones y tendencias, anticipan posibles demandas y optimizan la accesibilidad, calidad y utilidad de los datos y documentos para la sociedad.
Para comprender en qué consiste la transparencia predictiva, es fundamental dimensionar la inteligencia artificial como un concepto amplio, enfocado en el desarrollo de tecnología capaz de emular procesos propios de la inteligencia humana. Dentro de este espectro, la transparencia como política pública se nutre del aprendizaje automático, identificando patrones en datos masivos, segmentando y clasificando información, y elaborando cálculos y predicciones.
Proyecto piloto en Transparencia Predictiva
Teniendo presente el potencial que ofrecen las nuevas tecnologías y la información contenida en la Plataforma Nacional de Transparencia (PNT), la Dirección General de Gobierno Abierto y Transparencia del INAI llevó a cabo, de manera colaborativa, la construcción de un modelo automatizado de gestión de información para desarrollar el primer proyecto piloto de transparencia predictiva en México.
Este implicó la implementación de una metodología basada en inteligencia artificial para analizar datos y aplicar técnicas de limpieza, procesamiento y clasificación de información. Posteriormente, con base en la segmentación de los diversos conjuntos de datos (configuración de clústers), se diseñó y aplicó una red neuronal de memoria a corto y largo plazo (LSTM) para generar predicciones sobre futuras demandas de información asociadas a cada clúster, indicando los momentos específicos en los que estas demandas surgirán para cada institución pública analizada.
Casos de estudio: IMSS y SSPC
Instituto Mexicano del Seguro Social (IMSS)
El IMSS es la institución pública que ha recibido el mayor volumen de SAI en México, alcanzando un total de 524,309 solicitudes desde 2016. Para este ejercicio, el modelo se probó analizando diferentes periodos en los que esta entidad recibió distintas cantidades de solicitudes, con pruebas anuales, trianuales y quinquenales.
Como resultado, el modelo alcanzó una “exactitud para datos nuevos” del 97.95%, incluso en el periodo más corto utilizado (un año, 2024), lo que indica que predice correctamente en casi todas las ocasiones. Para este análisis, se utilizó una base de datos de 44,430 solicitudes, segmentando la información en 30 clústers. De esta manera, el Error Cuadrático Medio (MSE) y el Error Absoluto Medio (MAE) variaron significativamente entre clústers, identificando en algunos de ellos una mayor calidad de agrupamiento y nivel de predicción.
Cabe señalar que la mayoría de los clústers presentaron errores bajos. En este sentido, al realizar una revisión exhaustiva del segmento con menor error y con un valor de Silhouette superior a 0.700 (clúster 22), se identificaron temáticas como el traspaso de recursos entre subcuentas de cesantía, vejez y cuota social, gestionados por la CONSAR y las AFORES, entre otros elementos.
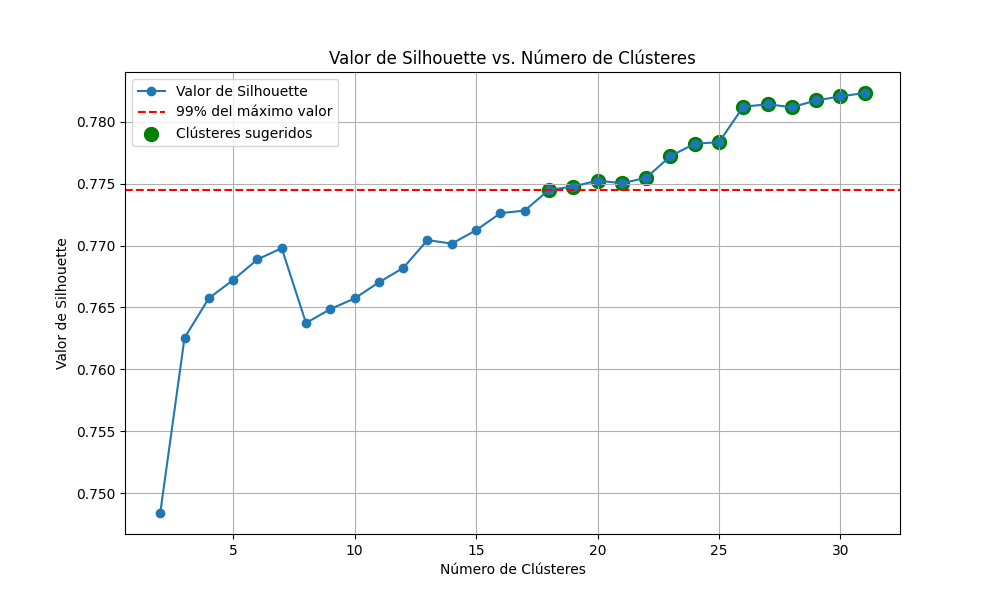
Gráfico 1. Índice de Silhouette para 30 clústers del IMSS con periodicidad de 1 año
En la Gráfica 1, cada punto representa un clúster generado a partir del algoritmo K-means. Para ello, el modelo desarrolló una serie de relaciones semánticas, agrupadas mediante dicho algoritmo. En esta línea, para cada valor se calculó el Índice de Silhouette, midiendo así la calidad del agrupamiento. Los valores superiores a 0.700 son deseables, por lo que, considerando la gráfica, podemos señalar que al menos la mitad de los agrupamientos presentan una calidad adecuada.
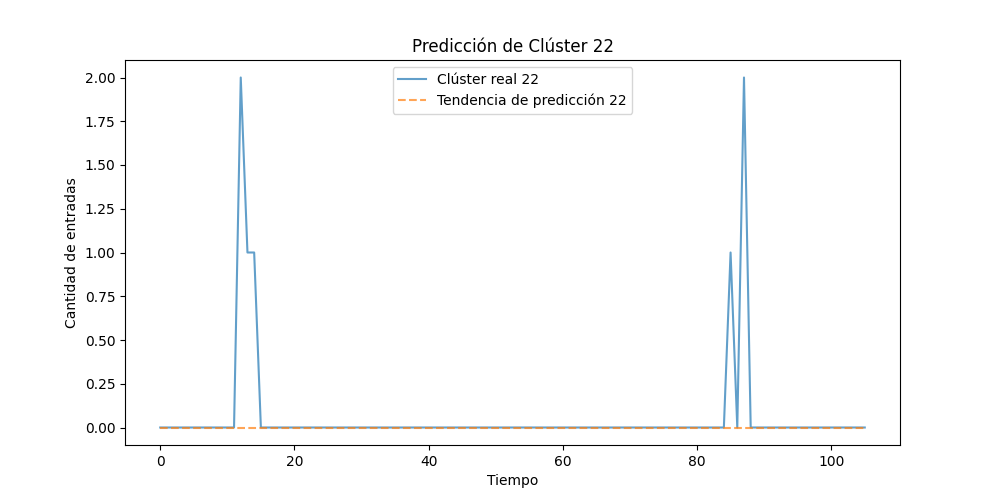
Gráfico 2. Predicción de tendencias de datos del IMSS relativos al cluster 22.
La Gráfica 2 representa los momentos del año inmediato posterior (2025) en los que se espera que las personas usuarias demanden información (predicción de necesidades informacionales) relacionada con las temáticas del clúster 22 en este caso de estudio. De modo que, considerando el periodo de análisis (20/12/2023 – 18/12/2024), se estima que dichas demandas ocurran principalmente durante la primera quincena de febrero y agosto de 2025. En esta gráfica, el eje X (horizontal) representa el tiempo, expresado en múltiplos de 10 para cada mes del año; mientras que el eje Y (vertical) indica el número de veces que se espera que se presenten demandas de información vinculadas al segmento analizado.
Secretaría de Seguridad y Protección Ciudadana (SSPC)
En el caso de la SSPC, con un análisis de 2,010 solicitudes durante 2024 (21/12/2023 – 18/12/2024), el nivel de predictibilidad es distinto pero mantiene un margen de precisión considerable, pues la exactitud del modelo es de 75.62%, al mismo tiempo, dispone de errores bajos. En este ejercicio, el agrupamiento con mejor desempeño para una agrupación de 30 clústers correspondió al segmento 19, que se relaciona con temáticas diversas pero con tendencias muy definidas en ciertos periodos.
Las tendencias en la demanda de información se orientan a informes de delitos, incidencias delictivas, homicidios, robos, y seguridad en carreteras, así como solicitudes de datos sobre personas migrantes aseguradas, puntos de control migratorio y operativos de seguridad en fronteras.
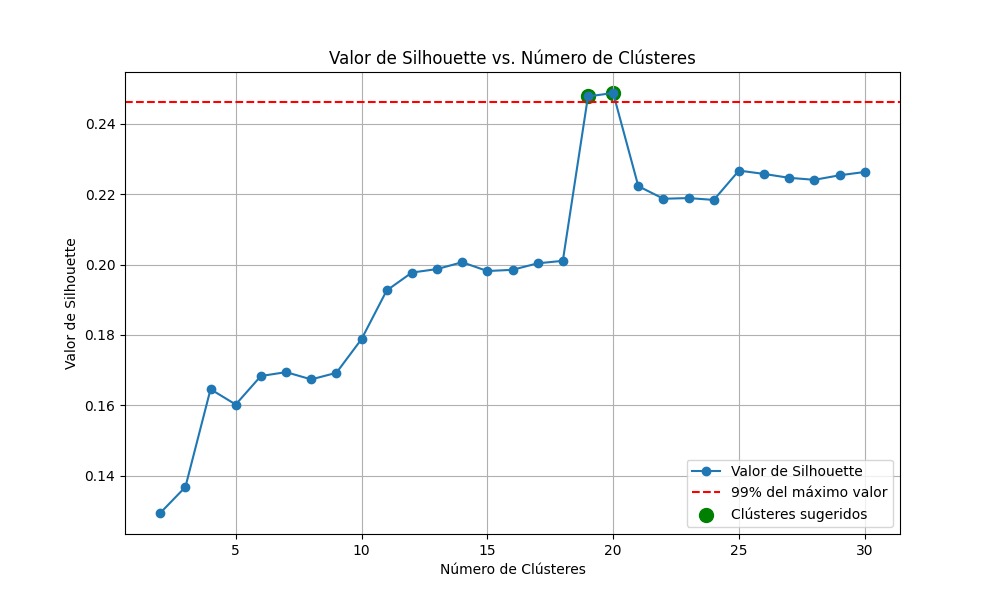
Gráfico 3. Índice de Silhouette para 30 clústers de la SSPC con periodicidad de 1 año
De acuerdo con las pruebas realizadas con los datos de la SSPC, se observó una calidad de agrupamiento deficiente, lo que podría deberse a un bajo volumen de datos o a la presencia de patrones de información altamente irregulares, factores que dificultan una segmentación más precisa por parte del modelo.
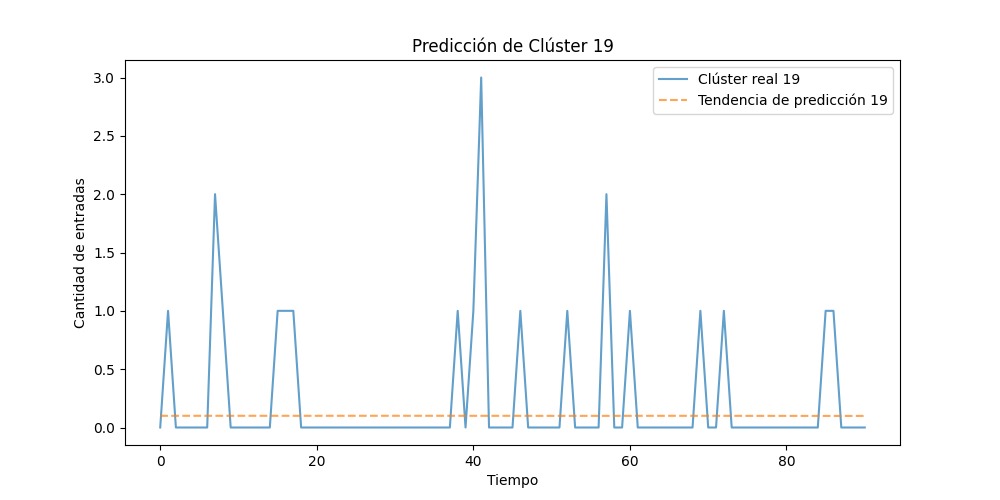
Gráfico 4. Predicción de tendencias de datos de la SSPC relativos al cluster 19.
Por su parte, la tendencia en la predicción de las temáticas del cluster 19 indica que entre enero y febrero, así como en los meses de abril y junio, existirán picos de alta demanda de información sobre las temáticas agrupadas en este cluster.
Perspectivas de la Transparencia Predictiva en México
La transparencia predictiva tiene un potencial prometedor. El uso de inteligencia artificial y análisis de datos, aplicado a las características de las instituciones públicas y a las necesidades de información, contribuye al fortalecimiento del derecho a la información y las distintas vertientes de transparencia. Además, ofrece una oportunidad valiosa para optimizar recursos y esfuerzos, al anticipar futuras cargas de trabajo en la gestión de información.
Resulta fundamental avanzar en la consolidación del enfoque teórico-práctico de la transparencia predictiva y, en el marco del nuevo diseño institucional en materia de transparencia en México, visualizar una política pública de esta naturaleza con aplicación transversal y alcance nacional. En la medida en que exista voluntad y capacidad institucional, así como recursos humanos, materiales y presupuestarios suficientes para este tipo de proyectos, tanto el Estado mexicano como los distintos sectores de la población podrán beneficiarse significativamente.
El impacto positivo de la transparencia predictiva en la sociedad y en las instituciones públicas dependerá de su capacidad de prueba y mejora continua (aún deben implementarse ajustes sobre el proyecto piloto) y de su efectividad para traducirse en la publicación de información oportuna, accesible, de calidad y utilidad para los distintos sectores.
Más información
Si tienes alguna pregunta o deseas conocer más información, puedes llenar el siguiente formulario.